第六节 中国城市空间分布
在结束本章之前,我们还要分析城市空间分布。重点是以中国城市空间分布为例,分析空间分布类型、市镇密度及空间分布模式的演变。
一、空间分布类型
我们可以用归纳法,将城市空间分布归纳为规则的或不规则的分布,聚集的、随机的或均匀的分布。最邻近分析指出,当最邻近指数为零时,属聚集分布;当最邻近指数为1时,属随机分布;当最邻近指数大于1时为均匀分布。而中心地学说描述的城市体系的最近邻指数为2.15,因而,可以说,中心地均匀分布系统只是城市空间统计分布的一个极端。
城市空间分布是动态的,其发展演变与经济、社会发展密切相关,具有明显的阶段性:
(1)离散阶段(低水平均衡阶段):对应于自给自足式,以农业为主体的阶段,以小城镇发展为主,缺少大中城市,没有核心结构,构不成等级系统。
(2)极化阶段:对应于工业化兴起、工业迅速增长并成为主导产业的阶段,中心城市强化。
(3)扩散阶段:对应于工业结构高度化阶段,中心城市的轴向扩散带动中小城市发展,点—轴系统形成。
(4)成熟阶段(高级均衡阶段):对应于信息化与产业高技术化发展阶段,区域生产力向均衡化发展,空间结构网络化,形成点—轴—网络系统,整个区域成为一个高度发达的城市化区域。
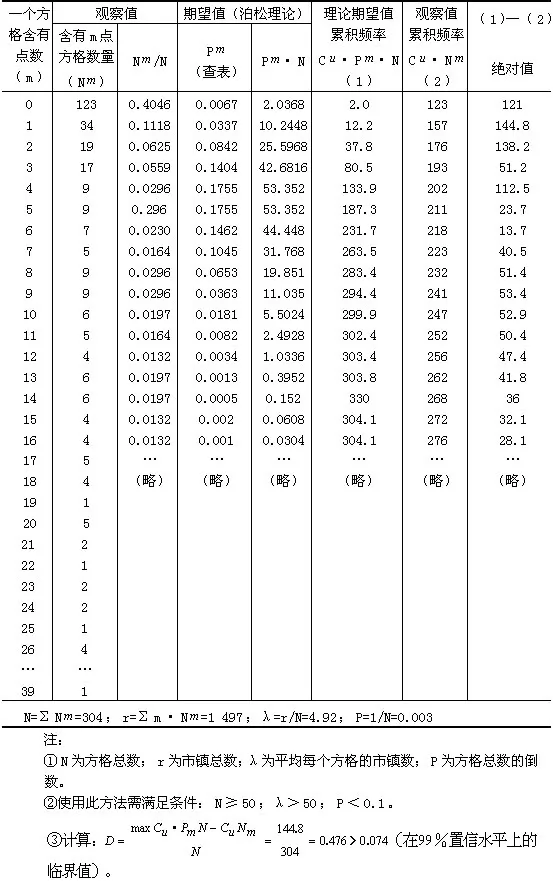
我们曾采用柯尔摩哥洛夫-史密尔诺夫公式( Kolmogorov-Smirnov)和罗伦兹曲线(Lovenz Curve)来检验我国 1978年1497座万人以上城镇的空间分布类型。
首先,使用方格分析法构造实际频率数组,并用柯尔摩哥洛夫-史密尔诺夫公式对城镇分布是否服从于泊松分布,即是否属于随机型进行检验。如果计算的D值小于查表的临界值,城镇分布服从泊松分布,即为随机型。否则为非随机型。
在全国地图上将全国划分为304个小方格子,观察每方格所包含的城镇数,检验结果见表8-4。从表中可知,计算的结果,D值(0.476)大于99%置信水平上的临界值(0.074),说明我国万人以上的市镇分布不是泊松分布,即不属随机型。
接着用罗伦兹曲线检验我国城镇分布属聚集型还是均匀型。罗伦兹曲线是用观察数据的累积百分数绘成的曲线。如果城镇分布是均匀的,则累积百分比曲线就是对角线,如果累积百分比曲线在对角线以下,则表示城镇分布是趋向集中的,其集中程度可用I指数表示:

I值越小,空间分布越集中。根据表8-4中的方格观察数据进行计算,并绘成罗伦兹曲线图。计算结果为I=1744.75/5000≈34.9%,它告诉我们,我国万人以上的城镇分布属集聚型。
经过30多年的建设,在我国西半部市镇稀少的地区出现不少新城镇,城镇分布的集聚程度有所缓和,这一点可从1953、1963、1978年我国城镇分布的最邻近分析的结果得到证明。1953年最近邻指数为0.8501,1963年为0.9050,1978年为0.9163,愈来愈接近1,说明我国城镇分布愈来愈接近随机分布,但到1978年为止,仍然为聚集分布。
表8-4 柯尔摩哥洛夫-史密尔诺夫D值检验表
我国市镇分布主要集中在东半部。以京广铁路和京哈铁路为界,东半部集中了我国特大城市9座,占特大城市总数的69.23%,大中城市61座,占70.93%,小城市和万人以上的城镇671座,占48%,而其土地面积仅占全国的1/7。具体而言,主要集聚在几个平原三角洲和交通线上,初步形成了辽中南、京津唐、长江三角洲和珠江三角洲四个规模特别大的城市集聚区。
二、城镇密度
城镇分布还可用城镇密度度量。1978年我国每千平方千米的国土上平均有万人以上城镇0.156座。正如上面所说,我国城镇分布属集聚型,因而城镇密度省际差异大。江苏、浙江、安徽、广东和福建密度最大,每千平方千米有万人以上城镇多于0.410座;江西、湖北、河南、山东、湖南、吉林、辽宁和河北等密度较大,每千平方千米在0.227—0.409座之间;四川、广西、山西、贵州、黑龙江和陕西密度较小,每千平方千米0.117—0.226座;云南、内蒙、甘肃、宁夏、新疆、青海和西藏密度最低,每千平方千米少于0.116座。将上述资料绘成我国各省区城镇密度图,可以明显地看出我国各省城镇密度从东向西有规律地递降。
我国各省区城镇密度的省际差异,是自然、政治、经济、人口和历史等因素综合作用的结果。在某种意义上说,经济、人口因素对城镇密度的影响,已经反映了自然、政治、历史等方面的作用。为此,根据资料收集与数量化的可能性以及省际的可比性,选择了经济和人口因素方面的六个因子进行回归分析,试图对平均密度的省际差异进行定量的解释。选择及计算结果如表8-5。
表8-5因子选择与资料矩阵

表8-6城镇密度省际差异回归分析结果
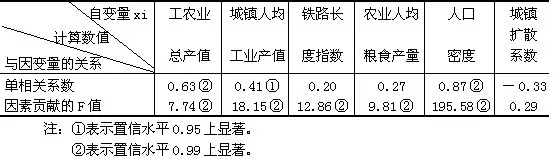
表8-6告诉我们,六个因子中,人口密度与城镇密度的相关性最显著,相关系数为0.87,因素贡献的F检验值最大,为195.58,说明人口密度较大的省区,城镇密度也大。东半部省区一般是人口多,土地面积小,人口密度大,虽然城镇非农业人口占总人口的比例并不很高(一般为12%左右),但城镇非农业人口的绝对数都很大。城镇数目多,因此形成较高的城镇密度。相反,西半部省区大多土地辽阔,人口稀少,虽城镇非农业人口占总人口的比例较高(一般在20%左右),但城镇人口的绝对数却很少,城镇数目不多,因此城镇密度低。
表8-6还告诉我们,国民经济发展的规模和水平与城镇密度关系也很大。工农业总产值可以衡量国民经济发展的程度,它与城镇密度的相关系数较高(0.63),因素贡献的F检验值可在99%置信水平上显著。说明国民经济越发达的省区,其城镇数目越多,城镇密度越大。城镇人均工业产值大体上反映了各省区的工业技术水平和劳动生产率的高低,进而反映了工业发展概况。城镇人均工业产值与城镇密度的相关系数和F值都较高,分别为0.41、18.15,说明人均工业产值越高的省区,城镇密度越大。各省区铁路长度指数,农业人均粮食产量与城镇密度的单相关不显著,但两者的因素贡献的F检验都在99%的置信水平上显著,因此,被选入了回归方程。而城镇扩散系数与城镇密度的相关关系不显著,F值最小,因此未被选入回归方程。最后的回归方程为:
y=0.1033+0.0004x1-0.0008x2-0.0012x3+0.0006x4+0.0013x5
由于回归方程的复相关系数大(R=0.96),F值高(50.36),估计标准误差小(0.0635),估计值与实际值相比,超过两个标准误差的省区只有山东。因此,该回归方程能较好地解释我国各省区城镇密度的差异。
本文标题:我国城市空间分布
手机页面:http://m.dljs.net/dlsk/chengshi/25164.html
本文地址:http://www.dljs.net/dlsk/chengshi/25164.html
